
エクセルは計算や文字の入力、図表、グラフの作成など、さまざまな機能があります。エクセルは機能数に見合う、表現の幅が広いソフトで、複数の関数を組み合わせると細かい条件付けが可能になる点が特徴的です。関数単体では実現できなかったことが出来るようになります。
この記事では、エクセルの文字列の抽出の仕方を解説します。文字列の抽出とは何か、どのような時に使うのか、といった概要から、いざ使う際の実践例を解説しているのでぜひ参考にしてください。
目次
エクセルにおける文字列の抽出とは?

そもそもエクセルにおける文字列の抽出とは、何を指しているのでしょうか?難しく考える必要はなく、シンプルに考えれば大丈夫です。
例えば、「東京都渋谷区神宮前111-111」という住所がA1セルに入っていた場合に、「東京都」や「渋谷区」といった情報だけを抽出することを指しています。
下記の画像にあるように、文字列の抽出機能を使えば、全員分の出身地の抽出が可能です。セル1つに含まれる情報が多すぎる際に、文字列抽出を使って、スッキリとした視認性の高い表作成に役立ちます。
文字列の抽出の仕方
文字列の抽出の仕方は以下の3通りです。
・文字列の先頭から抽出(LEFT関数)
・文字列の最後から抽出(RIGHT関数)
・文字列の真ん中で抽出(MID関数)
いずれも対応する関数があり、文字列のどこを抽出したいのかによって使い分けが必要です。ただ、どの関数も数式はほとんど同じで、どれか1つ覚えてしまえば、他2つの関数の使い方も分かりやすいので、安心してください。
LEFT関数で文字列の先頭から抽出

LEFT関数は、文字列の先頭から数え始めて文字を抽出する関数です。数式は下記のようになります。
=LEFT(文字列,文字数)
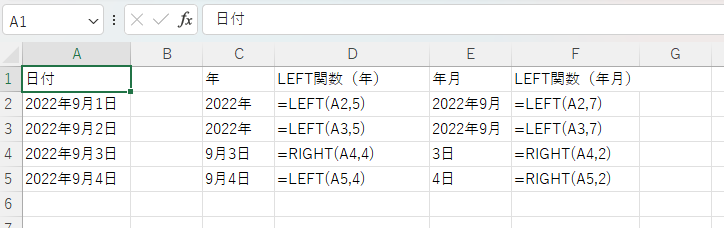
第1引数の文字列は、文字を抽出する元の文字列が入ったセルを指します。C2セルに入力したLEFT関数では、「2022年9月1日」と書かれたA2セルを引数にしました。ここで第1引数に間違えて文字列のないセルを選ぶと何も表示されなくなります。
第2引数には、何文字目までを抽出するか半角または全角の数字で指定します。上記の画像では、5文字目までを選択すると「2022年」、7文字目までを選択すると「2022年9月」という文字列が抽出されました。第2引数が1なら「2」、第2引数が3なら「202」となります。
RIGHT関数で文字列の最後から抽出
RIGHT関数は、文字列の末尾から数え始めて文字を抽出する関数です。数式は下記のようになります。
=RIGHT(文字列,文字数)
第1引数の文字列は、LEFT関数と同じく文字を抽出する元の文字列が入ったセルを指します。C4セルに入力したRIGHT関数では、「2022年9月3日」と書かれたA4セルを引数にしました。LEFT関数と同様に第1引数に間違えて文字列のないセルを選ぶと何も表示されなくなります。
第2引数には、末尾から何文字目までを抽出するか半角または全角の数字で指定します。上記の画像では、4文字目までを選択すると「9月3日」、2文字目までを選択すると「9月3日」という文字列が抽出されました。
MID関数で文字列の真ん中を抽出

文字列の先頭、末尾を抽出したら、真ん中は抽出できないのかと思いますよね。MID関数を使えば文字列の途中でも抽出できます。
LEFTとRIGHT関数は、数え始める位置が端だったので片方の文字数を指定すれば動きましたが、MID関数はそうもいきません。数え始めと何文字抽出するかを指定する必要があります。数式は下記の通りです。
=MID(文字列,開始位置,文字数)
上記の画像では、C6セルで左から6番目、2文字を抽出する数式を記入し、「9月」という出力結果を得られました。E6セルでは3番目から5文字を抽出して「22年9月」と出力されています。このようにして、MID関数を使うと文字列の途中を抽出できます。
エクセルで指定した文字列の位置を調べるには?

これまで、LEFT、RIGHT、MID関数を解説してきましたが、どれも開始位置や抽出する文字数を指定しなければなりませんでした。便利な関数ですが、抽出する文字数を手動で変える必要があります。
例えば、2022年のように決まって5文字の場合はオートフィルで関数の式を量産できますが、北海道、和歌山県、東京都といった文字数が変動する場合は、1つずつ関数の式を変えなければなりません。
そのような場合に便利なのがFIND(ファインド)関数です。指定した文字列が何文字目にあるのかを表示します。
FIND関数がカウントする対象
エクセルのFIND関数は、「都」や「区」、ハイフン、数字など、指定した文字列が何文字目に位置しているかを出力する関数です。日本語、英語、数字、記号、全角、半角、大文字、小文字に関係なく、全て1文字としてカウントされます。
FIND関数の数式・引数

FIND関数は、下記の数式で表されます。
=FIND(検索文字列,対象,開始位置)
3つの引数があるため、難しく捉えてしまうかもしれませんが、実は簡単な内容です。
第1引数:検索文字列
検索文字列は、位置を調べたい文字を記入します。例えば「都」や「1」「-」といった漢字、数字、記号、あらゆるものを文字に指定できます。ただし、数字以外はダブルクオーテーションマークで囲わなければなりません。
エクセルで関数を使う際は、ダブルクォーテーションで囲うことで、ひらがな、カタカナ、漢字、記号、アルファベットといった文字を認識します。忘れるとエラーが発生するため、注意しましょう。
第2引数:対象
第2引数の対象は、参照先のセルを指しています。間違えて、検索したい文字列を含まない誤ったセルを指定すると、#VALUE!エラーが発生するので注意しましょう。
第3引数:開始位置
開始位置は、文字の検索を始める位置を数値で指定します。基本的には1を指定し、省略すると、自動的に1が反映される仕様です。ただ、開始位置を指定しても、対象セルの先頭文字からの位置が返されるので特に考慮する必要はありません。
FIND関数の使う際の注意点

FIND関数を使う際は、「どのような文字列を検索するのか」「どのセルを参照先(対象セル)に指定するか」の2つに注意しましょう。この2つを明確にしておかないと各種エラーが発生する可能性が高くなります。
FIND関数で#VALUE!エラーが出た場合の対処法
FIND関数を使っていると#VALUE!エラーが発生することが多くあります。主な原因は次の2つです。
・検索文字列を間違えている(第1引数のミス)
・対象のセルに指定した文字列が含まれていない(第2引数のミス)
「東京都新宿区」という文字に対して「市」と検索してしまうなど、簡単なミスでエラーが発生します。第1引数で検索文字列を変更するか、第2引数で指定する対象を変更しましょう。
FIND関数をLEFTと組み合わせる
FIND関数は単体で使う分には使い道が広がりませんが、LEFT関数と組み合わせることで非常に便利な機能を使えます。指定した文字数分だけ抽出するのではなく、指定された文字までを検索して抽出できるようになるので、大変おすすめです。

さまざまな住所が記入されたA列に対して、LEFT関数とFIND関数を組み合わせれば、県までの文字列を抽出できます。県名によって文字数が変わるため、LEFT関数だけで出力するのは難しいです。しかし、FIND関数を組み合わせれば「県」という文字に合わせて抽出文字を変えられます。
IFERROR関数と組み合わせる
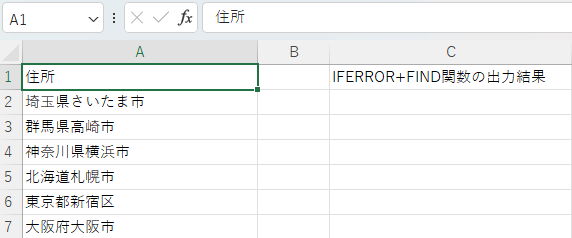
上記の画像のように、東京”都”、北海”道”、大阪”府”、埼玉”県”といった住所が記入されている場合、LEFT関数とFIND関数を組み合わせただけでは、オートフィルで関数を量産できません。「都・道・府・県」の文字の位置を調べる場合、LEFT関数とFIND関数に加えてIFERROR関数を組み合わせましょう。
エラー値を別の文字に置き換えてくれるため、検索した際に#VALUE!エラーが表示されることを防げます。小さなミスでエラーが発生しやすいFIND関数を扱う際にピッタリの関数です。
IFERROR関数とLEFT関数、FIND関数を組み合わせた数式は、下記のようになります。
=IFERROR(LEFT(A2,FIND(“都”,A2)),IFERROR(LEFT(A2,FIND(“道”,A2)),IFERROR(LEFT(A2,FIND(“府”,A2)),IFERROR(LEFT(A2,FIND(“県”,A2)),”検索文字列なし”))))
順番に都道府県の文字列をチェックして、該当するものがなければ「該当なし」と表示されます。ここでは日本の都道府県を調べるだけなので、アメリカ合衆国のアリゾナ州は「該当なし」と表示されます。

FIND関数とFINDB関数との違い

文字列の位置を検索するFIND関数には、FINDB関数というよく似た関数があります。ほとんど同じ名前ですが、どのような違いがあるのでしょうか?
数える対象が文字かバイトか
FIND関数は文字数を数え、FINDB関数はバイト(byte)数を数えます。FIND関数はあらゆる文字(ひらがな、カタカナ、漢字、アルファベット、数字、記号、大文字、小文字、全角、半角)を1つずつカウントします。一方のFINDB関数は、バイト数を数える関数です。
バイトとはデータの単位で、全角文字を2バイト、半角文字を1バイトとしてカウントします。「歌舞伎町123-456」という文字列でハイフン(-)を検索する場合、出力結果は「12」です。歌舞伎町は全角文字なので2バイトずつカウントされて8になります。
「123」という半角数字は1バイトずつカウントして3、つまりハイフンは12バイト目に該当するため、出力結果が12となる仕組みです。
FIND関数とSEARCH関数の違い
実はFIND関数の他にも、文字列の位置を検索する関数があります。それはSEARCH関数です。ここでは、FIND関数とSEARCH関数の違いについて解説します。
文字の区別が曖昧
FIND関数では全角文字と半角文字を分けて判別しますが、SEARCH関数は全角と半角を分けずに文字列を検索します。
例えば、FIND関数を使って全角の空白が入力されたセルに対し、半角の空白を検索すると、#VALUE!エラーが発生します。エラーが発生しないようにするには、引数を正しく修正するか、IFERROR関数によるエラーの回避が必要です。
一方のSEARCH関数はあいまい検索が可能で、大文字、小文字、全角、半角関係なしに、検索できます。
ワイルドカード
ワイルドカードをご存知でしょうか?ワイルドカードとは、特定の記号を用いて、~~を含む、~~から始まるといった曖昧検索ができるという機能です。例えばアスタリスク(*)を使うと、下記のような表し方ができます。
| *▲* | 「▲を含む」 |
| ▲* | 「▲から始まる」 |
| *▲ | 「▲で終わる」 |
このワイルドカード検索ができるのがSEARCH関数です。FIND関数ではワイルドカード検索ができません。
まとめ

エクセルで文字列を抽出する際は、LEFT関数、RIGHT関数、MID関数、FIND関数を使うのが便利です。単体では使い道が限られても、組み合わせると、応用の幅が利きます。LEFT関数とRIGHT関数とMID関数は文字数を指定して、文字列の抽出を行います。そこでFIND関数を使うことで、指定文字までの文字数を自動でカウントできるのがメリットです。


